Generating Structured Pseudo Labels for Noise-resistant Zero-shot Video Sentence Localization
Abstract
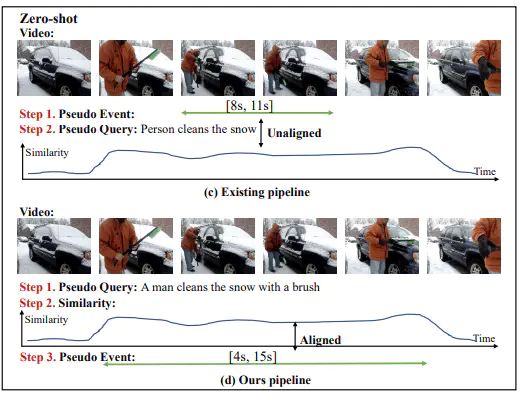
Video sentence localization aims to locate moments in an unstructured video according to a given natural language query. A main challenge is the expensive annotation costs and the annotation bias. In this work, we study video sentence localization in a zero-shot setting, which learns with only video data without any annotation. Existing zero-shot pipelines usually generate event proposals and then generate a pseudo query for each event proposal. However, their event proposals are obtained via visual feature clustering, which is query-independent and inaccurate; and the pseudo-queries are short or less interpretable. Moreover, existing approaches ignores the risk of pseudo-label noise when leveraging them in training. To address the above problems, we propose a Structure-based Pseudo Label generation (SPL), which first generate free-form interpretable pseudo queries before constructing query-dependent event proposals by modeling the event temporal structure. To mitigate the effect of pseudo-label noise, we propose a noise-resistant iterative method that repeatedly re-weight the training sample based on noise estimation to train a grounding model and correct pseudo labels. Experiments on the ActivityNet Captions and Charades-STA datasets demonstrate the advantages of our approach. Code can be found at https://github.com/minghangz/SPL.
Video
Citation
@inproceedings{zheng-etal-2023-generating,
title = "Generating Structured Pseudo Labels for Noise-resistant Zero-shot Video Sentence Localization",
author = "Zheng, Minghang and
Gong, Shaogang and
Jin, Hailin and
Peng, Yuxin and
Liu, Yang",
booktitle = "Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.acl-long.794",
pages = "14197--14209",
abstract = "Video sentence localization aims to locate moments in an unstructured video according to a given natural language query. A main challenge is the expensive annotation costs and the annotation bias. In this work, we study video sentence localization in a zero-shot setting, which learns with only video data without any annotation. Existing zero-shot pipelines usually generate event proposals and then generate a pseudo query for each event proposal. However, their event proposals are obtained via visual feature clustering, which is query-independent and inaccurate; and the pseudo-queries are short or less interpretable. Moreover, existing approaches ignores the risk of pseudo-label noise when leveraging them in training. To address the above problems, we propose a Structure-based Pseudo Label generation (SPL), which first generate free-form interpretable pseudo queries before constructing query-dependent event proposals by modeling the event temporal structure. To mitigate the effect of pseudo-label noise, we propose a noise-resistant iterative method that repeatedly re-weight the training sample based on noise estimation to train a grounding model and correct pseudo labels. Experiments on the ActivityNet Captions and Charades-STA datasets demonstrate the advantages of our approach. Code can be found at https://github.com/minghangz/SPL.",
}
Acknowledgement
This work was supported by the grants from the Zhejiang Lab (NO.2022NB0AB05), National Natural Science Foundation of China (61925201,62132001,U22B2048), CAAI-Huawei MindSpore Open Fund, Alan Turing Institute Turing Fellowship, Veritone and Adobe. We thank MindSpore for the partial support of this work, which is a new deep learning computing framework.