Abstract
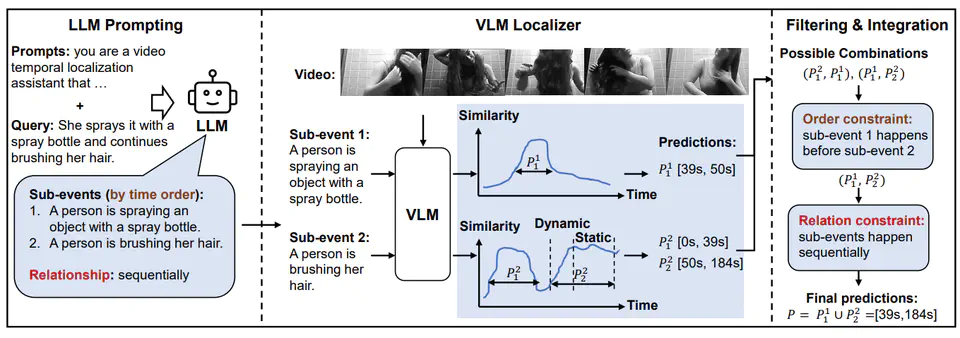
Video temporal grounding aims to identify video segments within untrimmed videos that are most relevant to a given natural language query. Existing video temporal localization models rely on specific datasets for training, with high data collection costs, but exhibit poor generalization capability under the across-dataset and out-of-distribution (OOD) settings. In this paper, we propose a Training-Free Video Temporal Grounding (TFVTG) approach that leverages the ability of pre-trained large models. A naive baseline is to enumerate proposals in the video and use the pre-trained visual language models (VLMs) to select the best proposal according to the vision-language alignment. However, most existing VLMs are trained on image-text pairs or trimmed video clip-text pairs, making it struggle to (1) grasp the relationship and distinguish the temporal boundaries of multiple events within the same video; (2) comprehend and be sensitive to the dynamic transition of events (the transition from one event to another) in the video. To address these issues, firstly, we propose leveraging large language models (LLMs) to analyze multiple sub-events contained in the query text and analyze the temporal order and relationships between these events. Secondly, we split a sub-event into dynamic transition and static status parts and propose the dynamic and static scoring functions using VLMs to better evaluate the relevance between the event and the description. Finally, for each sub-event description provided by LLMs, we use VLMs to locate the top-k proposals that are most relevant to the description and leverage the order and relationships between sub-events provided by LLMs to filter and integrate these proposals. Our method achieves the best performance on zero-shot video temporal grounding on Charades-STA and ActivityNet Captions datasets without any training and demonstrates better generalization capabilities in cross-dataset and OOD settings. Code is available at https://github.com/minghangz/TFVTG.
Video
Citation
@inproceedings{zheng-etal-2024-training,
title = "Training-free Video Temporal Grounding usingLarge-scale Pre-trained Models",
author = "Zheng, Minghang and
Cai, Xinhao and
Chen, Qingchao and
Peng, Yuxin and
Liu, Yang",
booktitle = "Proceedings of the European Conference on Computer Vision (ECCV)",
year = "2024"
}
Acknowledgement
This work was supported by grants from the National Natural Science Foundation of China (62372014, 61925201, 62132001, U22B2048).