
Abstract
Multi-modal Large Language Models (MLLMs) have achieved remarkable progress in video temporal grounding with reinforcement learning for generating reasoning paths. However, existing models often produce superficial reasoning, which offers limited guidance for precise temporal localization. This limitation stems from (1) inefficient random exploration and (2) reward functions that focus solely on the answer correctness while ignoring reasoning quality. To address these issues, we propose TaRO (Temporal-Aware Reasoning Optimization), a framework that explicitly enhances the model’s ability of thinking with time. First, we introduce a Constructive Reasoning Exploration that leverages pre-generated dense captions to construct reasoning paths grounded in explicit visual cues and timestamps, enabling efficient exploration of high-quality time-aware reasoning. Second, to evaluate reasoning quality, we design a Temporal-Sensitivity Reward. High-quality reasoning should be anchored to specific events and timestamps. If the event boundary under thinking is disrupted, such reasoning should become invalid, leading to a drop in the logit of the reasoning path. We utilize this drop as a critique of reasoning quality. Finally, TaRO follows a progressive curriculum, which starts by utilizing this reward to select better constructed reasoning paths, and evolves to a free exploration phase where the model autonomously generates effective reasoning. Experiments demonstrate that TaRO achieves state-of-the-art performance on VTG benchmarks. Code is available at https://github.com/oceanflowlab/TaRO.
🎥 Video
💡 Motivation
⚠️ The Problem: “Pretend to Think”
Current MLLMs often generate superficial reasoning that provides zero guidance for precise temporal localization.
- Inefficient Random Exploration
Blind guesses in a vast video search space rarely lead to quality reasoning. - Flawed Reward Mechanism
RL rewards only check final IoU, ignoring whether the reasoning actually uses visual & temporal cues.
✨ Our Solution: Thinking with Time
We propose TaRO (Temporal-Aware Reasoning Optimization), a framework that forces the model to master “Thinking with Time.”
High-quality reasoning anchors events to specific timestamps and visual evidence, enabling precise temporal localization.
🛠️ Method Overview
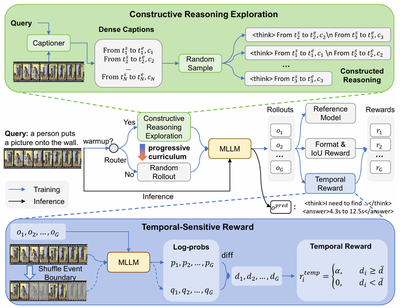
Constructive Reasoning
Pre‑generated dense captions supply atomic events with timestamps. By concatenating them, we construct informative reasoning paths that teach the model to identify critical visual cues and filter out distractors.
Temporal‑Sensitive Reward
Frames near ground‑truth boundaries are locally shuffled. If the reasoning truly relies on temporal structure, this perturbation breaks it, causing a confidence drop, which we use as a reward that enforces tight visual‑temporal coupling.
Progressive Curriculum
A two‑stage curriculum: first, the model learns from constructed reasoning trajectories; then it advances to a self‑exploration phase, autonomously refining strategies under both our temporal‑sensitive reward and standard IoU reward.
📊 Key Results
🏆 State‑of‑the‑Art on Four VTG Benchmarks
All experiments use Qwen2.5-VL-7B-Instruct as the base model. TaRO consistently surpasses the previous strongest RL‑based baseline, Time‑R1.
| Dataset | Metric | Time‑R1 | TaRO (Ours) | Δ Improvement |
|---|---|---|---|---|
| Charades‑STA | R1@0.5 | 60.8 | 64.8 | 🚀 +4.0% |
| ActivityNet | R1@0.5 | 39.0 | 39.8 | 🚀 +0.8% |
| QVHighlights | R1@0.5 | 66.2 | 69.4 | 🚀 +3.2% |
| TVGBench | R1@0.5 | 29.4 | 37.8 | 🚀 +8.4% |
📖 Citation
@InProceedings{Zheng_2026_ICML,
author = {Zheng, Minghang and Yin, Zihao and Yang, Yi and Peng, Yuxin and Liu, Yang},
title = {Temporal-Aware Reasoning Optimization for Video Temporal Grounding},
booktitle = {International Conference on Machine Learning},
year = {2026}
}