ResVG: Enhancing Relation and Semantic Understanding in Multiple Instances for Visual Grounding
Abstract
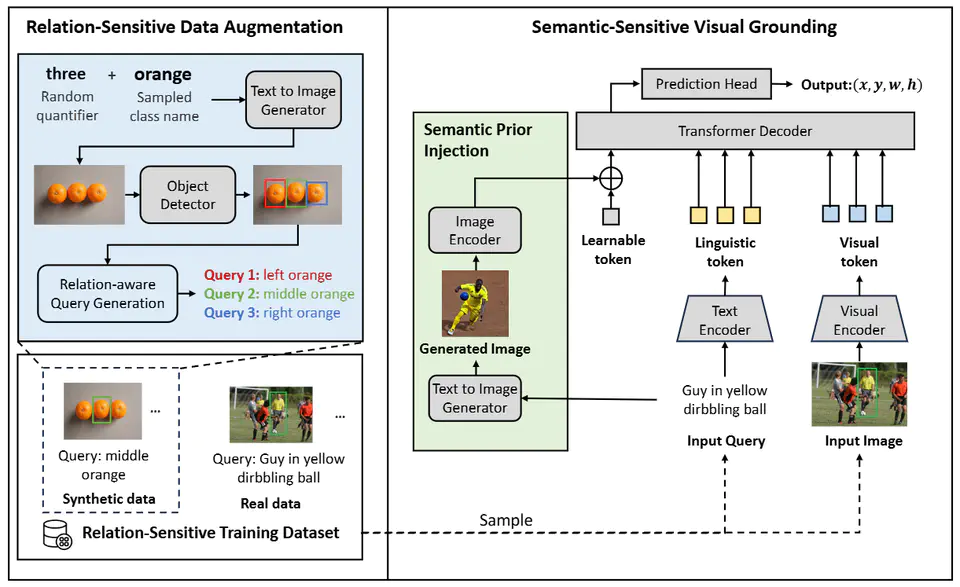
Visual grounding aims to localize the object referred to in an image based on a natural language query. Although progress has been made recently, accurately localizing target objects within multiple-instance distractions (multiple objects of the same category as the target) remains a significant challenge. Existing methods demonstrate a significant performance drop when there are multiple distractions in an image, indicating an insufficient understanding of the fine-grained semantics and spatial relationships between objects. In this paper, we propose a novel approach, the \textbf{Re}lation and \textbf{S}emantic-sensitive \textbf{V}isual \textbf{G}rounding (ResVG) model, to address this issue. Firstly, we enhance the model’s understanding of fine-grained semantics by injecting semantic prior information derived from text queries into the model. This is achieved by leveraging text-to-image generation models to produce images representing the semantic attributes of target objects described in queries. Secondly, we tackle the lack of training samples with multiple distractions by introducing a relation-sensitive data augmentation method. This method generates additional training data by synthesizing images containing multiple objects of the same category and pseudo queries based on their spatial relationships. The proposed ReSVG model significantly improves the model’s ability to comprehend both object semantics and spatial relations, leading to enhanced performance in visual grounding tasks, particularly in scenarios with multiple-instance distractions. We conduct extensive experiments to validate the effectiveness of our methods on five datasets. Code is available at https://github.com/minghangz/ResVG.
Video
Citation
@inproceedings{zheng-etal-2024-training,
title = "ResVG: Enhancing Relation and Semantic Understanding in Multiple Instances for Visual Grounding",
author = "Zheng, Minghang and Zhang, Jiahua and Chen, Qingchao and Peng, Yuxin and Liu, Yang",
booktitle = "Proceedings of the 31st ACM International Conference on Multimedia",
year = "2024"
}
Acknowledgement
This work was supported by grants from the National Natural Science Foundation of China (62372014, 61925201, 62132001, U22B2048).