Hierarchical Event Memory for Accurate and Low-latency Online Video Temporal Grounding
Abstract
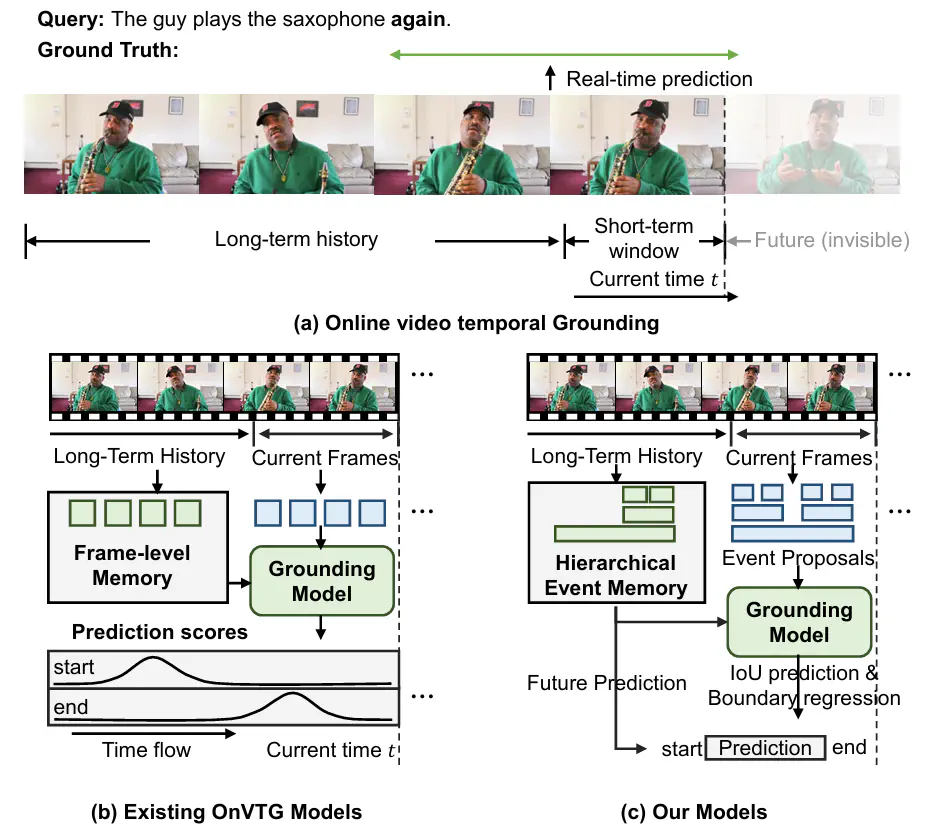
In this paper, we tackle the task of online video temporal grounding (OnVTG), which requires the model to locate events related to a given natural language query within a video stream. Unlike regular video temporal grounding, OnVTG requires the model to make predictions without observing future frames. As online videos are streaming inputs and can go on indefinitely, it is impractical and inefficient to store all historical inputs. The existing OnVTG model employs memory to store recent historical video frame features and predict scores indicating whether the current frame corresponds to the start or end time of the target event. However, these methods lack effective event modeling and cannot retain long-term historical information, leading to low performance. To tackle these challenges, we propose a hierarchical event memory for online video temporal grounding. We propose an event-based OnVTG framework that makes predictions based on event proposals that model event-level information with various durations. To efficiently preserve historically valuable event information, we introduce a hierarchical event memory that retains long-term historical events, allowing the model to access both recent fine-grained information and long-term coarse-grained information. To enable the real-time prediction of the start time, we further propose a future prediction branch that predicts whether the target event will occur in the near future and further regresses the start time of the event. We achieve state-of-the-art performance on the ActivityNet Captions, TACoS, and MAD datasets. Code is available at https://github.com/minghangz/OnVTG.
Video
Citation
@inproceedings{zheng-etal-2025-hierarchical,
title = "Hierarchical Event Memory for Accurate and Low-latency Online Video Temporal Grounding",
author = "Zheng, Minghang and
Peng, Yuxin and
Sun, Benyuan and
Yang, Yi and
Liu, Yang",
booktitle = "Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)",
year = "2025"
}