Weakly Supervised Temporal Sentence Grounding with Gaussian-based Contrastive Proposal Learning
Abstract
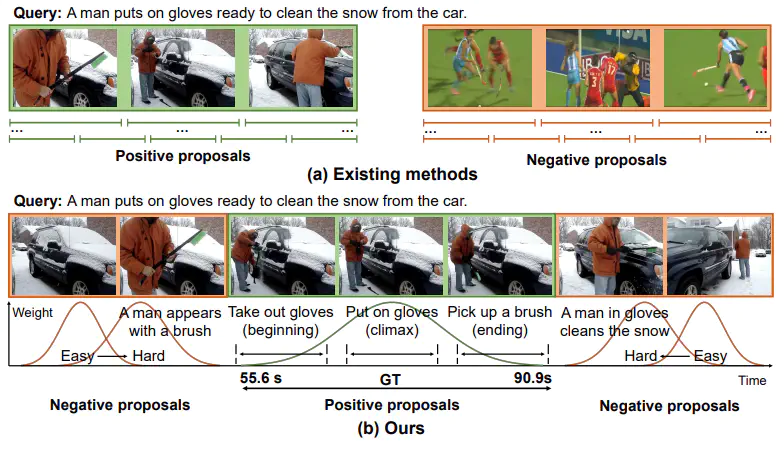
Temporal sentence grounding aims to detect the most salient moment corresponding to the natural language query from untrimmed videos. As labeling the temporal boundaries is labor-intensive and subjective, the weakly-supervised methods have recently received increasing attention. Most of the existing weakly-supervised methods generate the proposals by sliding windows, which are content-independent and of low quality. Moreover, they train their model to distinguish positive visual-language pairs from negative ones randomly collected from other videos, ignoring the highly confusing video segments within the same video. In this paper, we propose Contrastive Proposal Learning(CPL) to overcome the above limitations. Specifically, we use multiple learnable Gaussian functions to generate both positive and negative proposals within the same video that can characterize the multiple events in a long video. Then, we propose a controllable easy to hard negative proposal mining strategy to collect negative samples within the same video, which can ease the model optimization and enables CPL to distinguish highly confusing scenes. The experiments show that our method achieves state-of-the-art performance on Charades-STA and ActivityNet Captions datasets. The code and models are available at this https url.
Citation
@inproceedings{CPL_2022_CVPR,
title = {Weakly Supervised Temporal Sentence Grounding with Gaussian-based Contrastive Proposal Learning},
author = {Zheng, Minghang and Huang, Yanjie and Chen, Qingchao and Peng, Yuxin and Liu, Yang},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2022}
}
Acknowledgement
This work is supported by the grants from the National Natural Science Foundation of China (61925201, 62132001, U21B2025) and Zhejiang Lab (NO.2022NB0AB05).